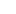 滚动
滚动非母语者写的文章 = AI 生成?气抖冷。
ChatGPT 火了以后,用法是真多。
有人拿来寻求人生建议,有人干脆当搜索引擎用,还有人拿来写论文。
论文... 可不兴写啊。
美国部分大学已经明令禁止学生使用 ChatGPT 写作业,还开发了一堆软件来鉴别,判断学生上交的论文是不是 GPT 生成的。
这里就出了个问题。
有人论文本来就写的烂,判断文本的 AI 以为是同行写的。
更搞的是,中国人写的英文论文被 AI 判断为 AI 生成的概率高达 61%。
这.... 这这什么意思?气抖冷!
非母语者不配?
目前,生成式语言模型发展迅速,确实给数字通信带来了巨大进步。
但滥用真的不少。
虽说研究人员已经提出了不少检测方法来区分 AI 和人类生成的内容,但这些检测方法的公平性和稳定性仍然亟待提高。
为此,研究人员使用母语为英语和母语不为英语的作者写的东西评估了几个广泛使用的 GPT 检测器的性能。
研究结果显示,这些检测器始终将非母语者写作的样本错误地判定为 AI 生成的,而母语写作样本则基本能被准确地识别。
此外,研究人员还证明了,用一些简单的策略就可以减轻这种偏见,还能有效地绕过 GPT 检测器。
这说明什么?这说明 GPT 检测器就看不上语言表达水平不咋地的作者,多叫人生气。
不禁联想到那款判断 AI 还是真人的游戏,如果对面是真人但你猜是 AI,系统就会说,「对方可能会觉得你冒犯了。」
不够复杂 = AI 生成?
研究人员从一个中国的教育论坛上获取了 91 篇托福作文,又从美国 Hewlett 基金会的数据集中摘取了 88 篇美国八年级学生写的作文,用来检测 7 个被大量使用的 GPT 检测器。
图表中的百分比表示「误判」的比例。即,是由人写的,但检测软件认为是 AI 生成的。
可以看到数据非常悬殊。
七个检测器中,美国八年级学生写的作文被误判的概率最高才 12%,还有两个零误判的 GPT。
中国论坛上的托福作文被误判的概率基本全部过半,最高误判概率可达 76%。
91 篇托福作文中的 18 篇被所有 7 个 GPT 检测器一致认为是 AI 生成的,而 91 篇中有 89 篇,都至少被一个 GPT 检测器误判。
从上图中我们可以看出,被所有 7 个 GPT 误判的托福作文在复杂度上明显低于其它论文。
这就印证了开头的那个结论 ——GPT 检测器会对那些语言表达能力有限的作者有一定偏见。
因此,研究人员认为,GPT 检测器应该多看点儿非母语者写的文章,样本多了,才能消除偏见。
接下来,研究人员把非母语者写的托福作文扔到了 ChatGPT 里,丰富一下语言,模仿母语者的用词习惯。
同时作为对照组,把美国八年级小孩儿写的作文也扔到了 ChatGPT 里,把语言简化了一下,模仿非母语者的写作特点。下图就是修正后的新判定结果。
我们可以发现,情况来了个大掉个儿,丰富了语言的托福作文错判率直线下降,低至 3%,最高也不过 19%。不像之前基本全部过半的错判率。
与之相反,八年级小孩儿写的作文的错判率直线上升,甚至还有一个 GPT 检测器的错判率高达 99%,基本全错。
因为,文章复杂度这个变量出现了变化。
这里研究人员就得出了一个结论,非母语者写的东西不地道,复杂度低,容易被错判。
这也就导向了一个技术问题,同时也是一个价值问题。以复杂度来判定 AI 还是人类是作者,是否合理、全面、严谨。
结果显然不是。
以复杂度为判断标准的情况下,非母语者吃了大亏,因为,他们是非母语者。
AI 润色 = 人类写的??
研究者认为,加强语言多样性不仅可以减轻对非母语者的偏见,还能让 GPT 生成的内容绕过 GPT 检测器。
为了证明这个观点,研究人员选取了 2022-2023 年间美国大学申请的入学论文题目,输入到 ChatGPT-3.5 里,一共生成了 31 篇假论文。
GPT 检测器一开始还挺有效,但是第二轮就不行了。这是因为,在第二轮中,研究人员把这些论文又扔到 ChatGPT 里润色了一下,用一些文学性的语言提升了文本质量。
这样一来,GPT 检测器的准确度就从 100% 直降到了 0%。如下图:
经过润色的文章复杂度相应也上升了。
与此同时,研究人员又用了斯坦福大学 145 个期末项目报告的题目,让 ChatGPT 生成摘要。
摘要经过润色以后,检测器判断的准确性继续下降。
研究者再次得出结论,润色过的文章很容易被误判,都是 AI 生成的,两轮就是比一轮强。
GPT 检测器?还是欠练
言而总之,总而言之,各种 GPT 检测器好像还是没能抓住 AI 生成和人类写作之间最本质的区别。
人的写作也分三六九等,仅靠复杂度判断,不甚合理。
抛开偏见因素不谈,技术本身也亟待改进。
参考资料: